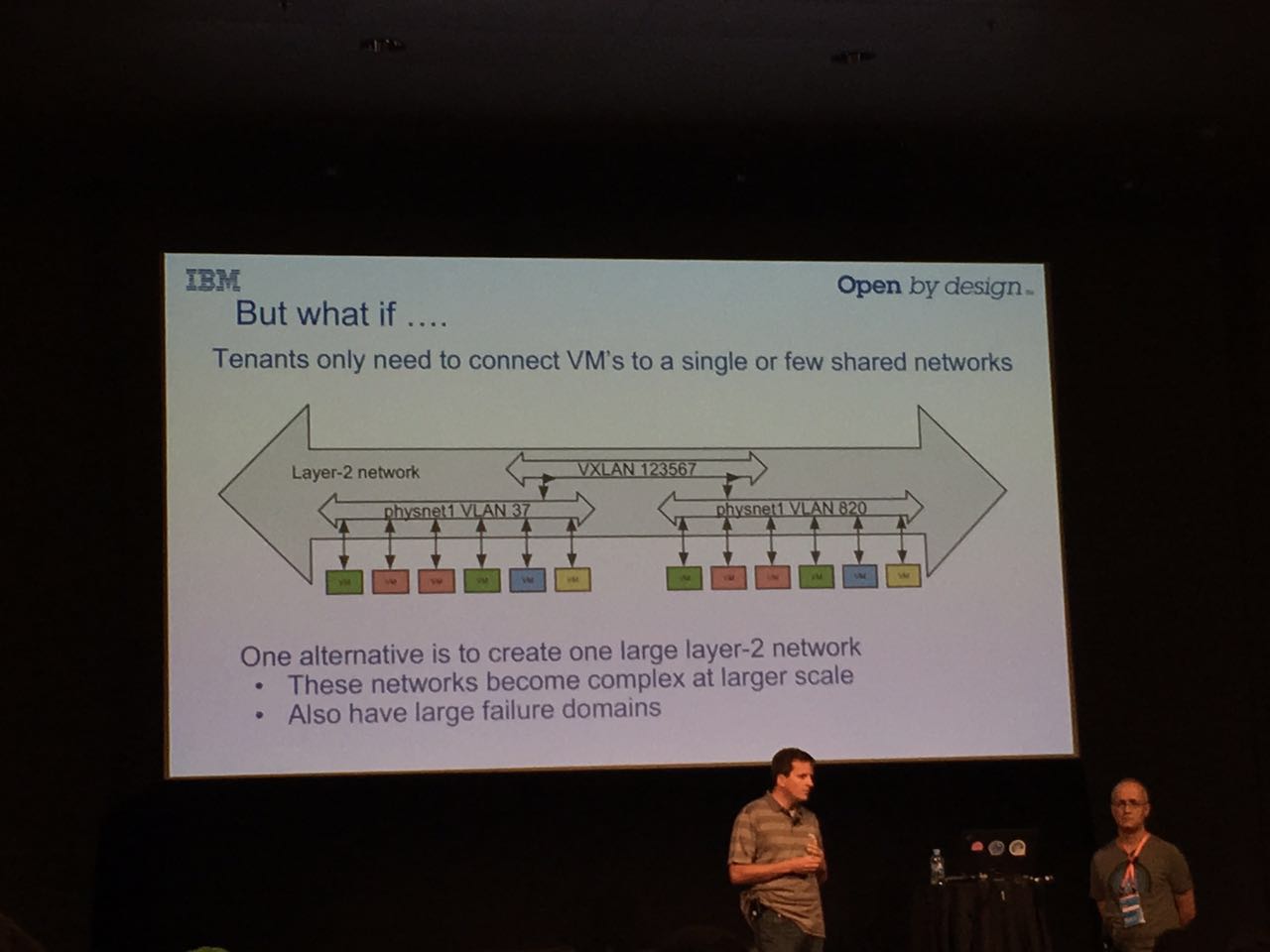
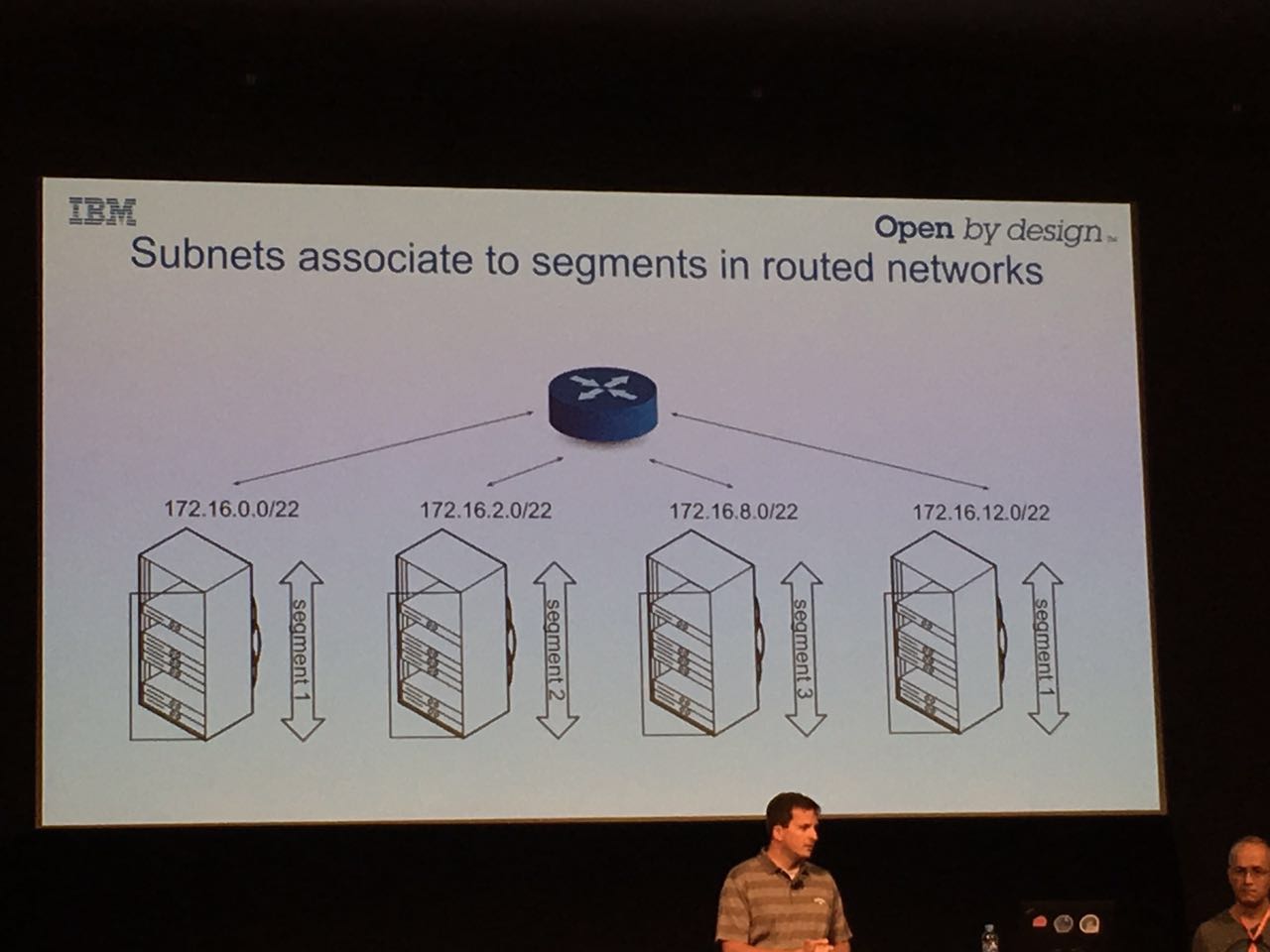
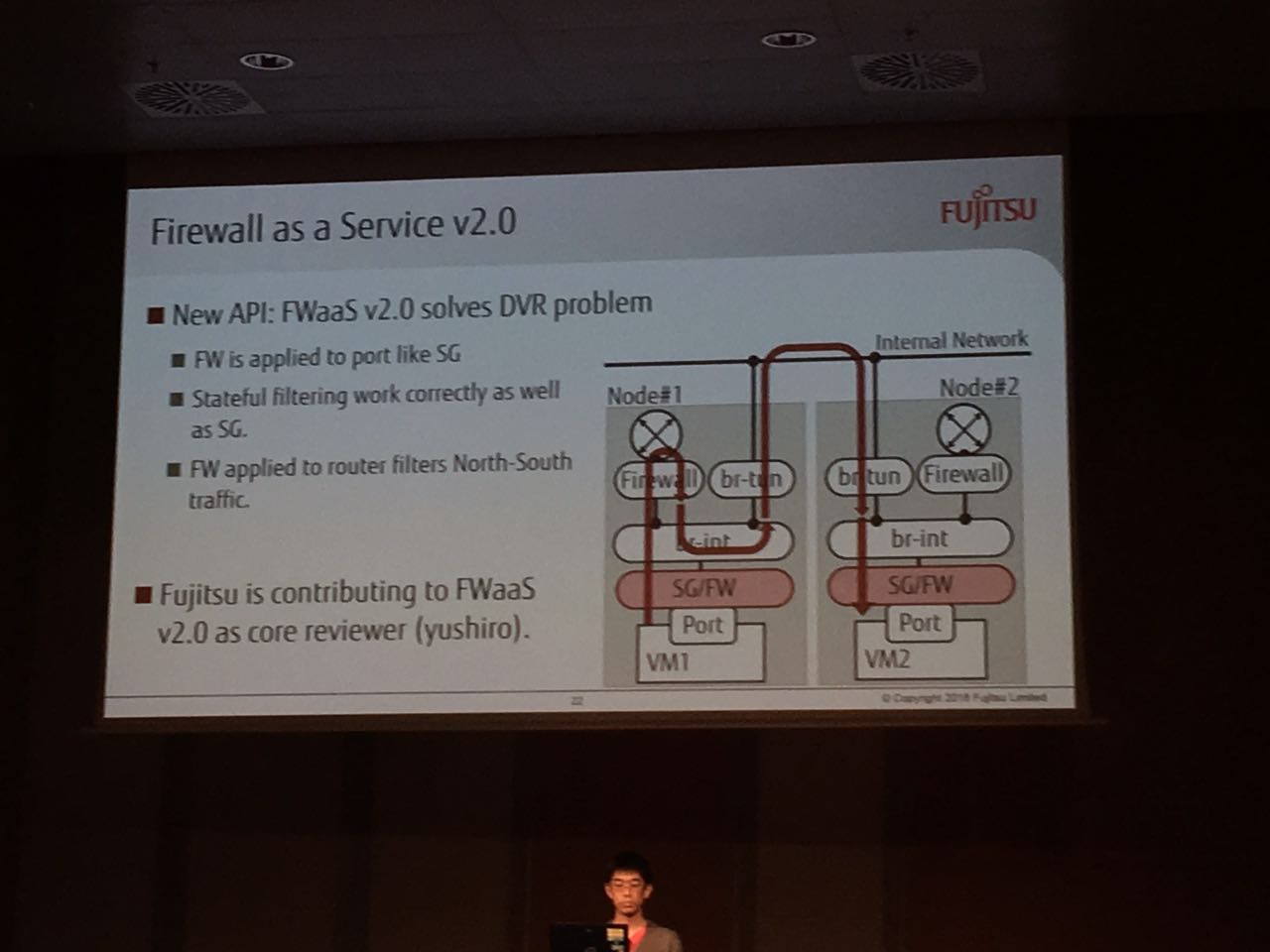
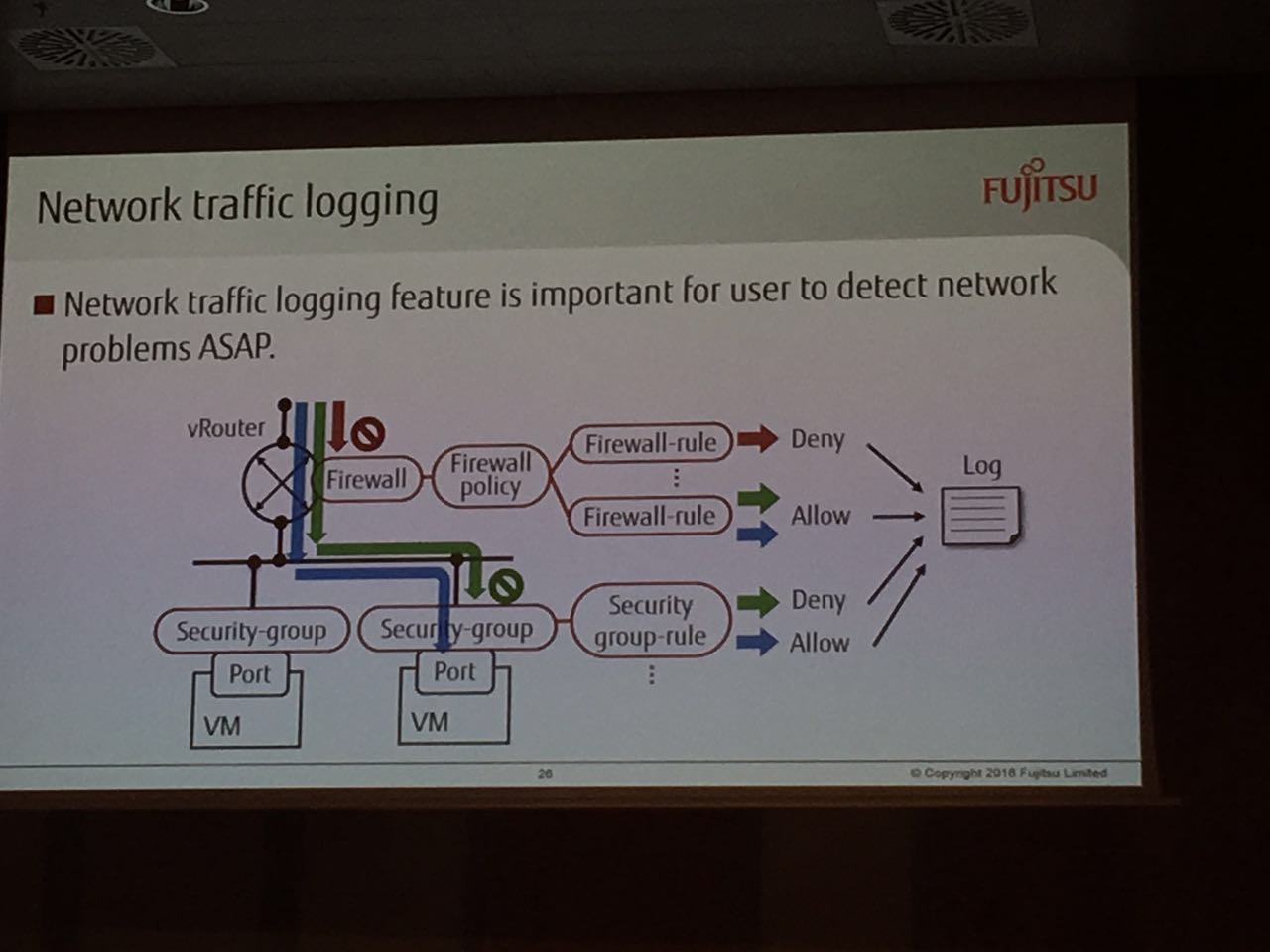
背景介绍
OpenFlow中的信息有很多种,以of13_msg_features_request为例,
原先在每个SW上起两个线程,一个接收,一个发送
1
2
3
//by:yhy 创建收发线程
pthread_create(&(sw->pid_recv), NULL, msg_recv_thread, (void *)&(sw->index));
pthread_create(&(sw->pid_proc), NULL, msg_proc_thread, (void *)&(sw->index));
这个是交换机中定义的结构体
typedef struct gn_switch
{
UINT1 ofp_version;
UINT1 state; //标记Switch是否启用
UINT1 pad[2];
INT4 index;
UINT8 dpid; /* 数据通路唯一的 ID。低 48-bits 是 MAC 地址,高 16 位是开发者定义。 */
UINT4 sw_ip;
UINT4 sw_port;
UINT4 sock_fd; //by:yhy 本交换机的socket连接句柄
UINT4 n_buffers; /*一次缓冲最大的数据包数。 */
UINT4 n_tables; /* 数据通路支持的表数量。 */
UINT4 n_ports; /* 交换机端口数量 */
UINT4 capabilities; /* 位图的支持"ofp_capabilities". */
switch_desc_t sw_desc; //交换机的描述信息
gn_port_t lo_port; //by:yhy Local openflow "port"
gn_port_t ports[MAX_PORTS];
neighbor_t *neighbor[MAX_PORTS]; //by:yhy 数组neighbor的索引与ports的索引匹配,neighbor[a]即为ports[a]的邻居节点
mac_user_t **users;
msg_driver_t msg_driver;
buffer_list_t recv_buffer; //by:yhy 接收缓存
UINT4 send_len;
UINT1 *send_buffer; /*长度:g_sendbuf_len*/
gn_flowmod_helper_t flowmod_helper;
gn_flow_t *flow_entries; //by:yhy 本交换机流表
gn_meter_t *meter_entries;
INT4 qos_type;
gn_qos_t* qos_entries;
gn_group_t* group_entries;
gn_queue_t* queue_entries;
pthread_mutex_t users_mutex;
pthread_mutex_t send_buffer_mutex;
pthread_mutex_t flow_entry_mutex;
pthread_mutex_t meter_entry_mutex;
pthread_mutex_t group_entry_mutex;
pthread_t pid_recv; //by:yhy 接收线程pid
pthread_t pid_proc; //by:yhy 处理线程pid
UINT8 connected_since;
UINT8 weight; //sw_weight
UINT1 sock_state; //socket status 判断当前线程是否拥有操作的权利"0"有效
pthread_mutex_t sock_state_mutex;
}gn_switch_t;
但是在每个包的处理过程中,会占用sw结构体中的buffer,并且每个包在存的时候都会加锁
1
2
3
4
5
6
7
8
static INT4 of13_msg_features_request(gn_switch_t *sw, UINT1 *fea_req)
{
LOG_PROC("OF13", "of13_msg_features_request -- START");
UINT2 total_len = sizeof(struct ofp_header);
init_sendbuff(sw, OFP13_VERSION, OFPT13_FEATURES_REQUEST, total_len, 0);
LOG_PROC("OF13", "of13_msg_features_request -- STOP");
return send_of_msg(sw, total_len);
}
这个是init_sendbuff的函数,把header中的数据写到sw结构中的buffer中
//初始化发送缓存
UINT1 *init_sendbuff(gn_switch_t *sw, UINT1 of_version, UINT1 type, UINT2 buf_len, UINT4 transaction_id)
{
UINT1 *b = NULL;
struct ofp_header *h;
pthread_mutex_lock(&sw->send_buffer_mutex);
if(sw->send_len < g_sendbuf_len)
{
b = sw->send_buffer + sw->send_len;
}
else
{
printf("........\n");
write(sw->sock_fd, sw->send_buffer, sw->send_len);
memset(sw->send_buffer, 0, g_sendbuf_len);
sw->send_len = 0;
b = sw->send_buffer;
}
h = (struct ofp_header *)b;
h->version = of_version;
h->type = type;
h->length = htons(buf_len);
if (transaction_id)
{
h->xid = transaction_id;
}
else
{
h->xid = random_uint32();
}
return b;
}
这个是send_of_msg函数,把消息的total_len加上去,然后解锁,最后通过交换机的发送线程发送 //发送openflow消息(解锁switch的发送缓存,具体发送在发送线程中执行)
1
2
3
4
5
6
7
INT4 send_of_msg(gn_switch_t *sw, UINT4 total_len)
{
// INT4 ret = 0;
sw->send_len += total_len;
pthread_mutex_unlock(&sw->send_buffer_mutex);
return GN_OK;
}
重构后:
思路,把消息进来存的buffer和sw解耦,sw的buffer每次只能被一个消息所占用,很影响效率,改动后如下,每次给一个包分配一个msgbuf,等写完之后,全部扔给sw_buffer,从而提高性能
1
2
3
4
5
6
7
8
static INT4 of13_msg_features_request(gn_switch_t *sw, UINT1 *fea_req)
{
Msg_Buf(struct ofp_header);
UINT2 nLen = sizeof(struct ofp_header);
init_header(pMsg,OFP13_VERSION,OFPT13_FEATURES_REQUEST,nLen,0);
send_packet(sw, msgbuf, nLen);
}
重构init_header,把header中的数据封装
void init_header(struct ofp_header *p_header,UINT1 of_version, UINT1 type, UINT2 len, UINT4 transaction_id)
{
p_header->version = of_version;
p_header->type = type;
p_header->length = htons(len);
if (transaction_id)
{
p_header->xid = transaction_id;
}
else
{
p_header->xid = random_uint32();
}
}
细节改动:
在common.h中加入
创建一个msgbuf给每个消息10K的大小的一个buffer,并初始化
1
2
3
4
5
6
#define MSG_MAX_LEN 10240
#define Msg_Buf(msgtype) \
char msgbuf[MSG_MAX_LEN];\
memset(msgbuf, 0, sizeof(msgbuf));\
msgtype* pMsg = NULL;\
pMsg = (msgtype*)msgbuf;
在conn-svr.h中加入
INT4 send_packet(gn_switch_t *sw, INT1* pBuf, UINT4 nLen);
void init_header(struct ofp_header *p_header,UINT1 of_version, UINT1 type, UINT2 len, UINT4 transaction_id);
在conn-svr.c中加入
直接将msgbuffer扔给sw_buffer处理
1
2
3
4
5
6
7
8
INT4 send_packet(gn_switch_t *sw, INT1* pBuf, UINT4 nLen)
{
pthread_mutex_lock(&sw->send_buffer_mutex);
memcpy(sw->send_buffer + sw->send_len, pBuf, nLen);
sw->send_len += nLen;
pthread_mutex_unlock(&sw->send_buffer_mutex);
}