什么是Zuul?
随着OpenStack持续集成的推广,基于OpenStack开源项目的性质,项目大,全球各地的开发人员多,变更提交频繁。Jenkins不能解决并发多、单依赖的问题,拉长了问题反馈时间。为解决该问题,源于OpenStack开源社区的基于ZUUL框架的 CI方案出现在我们的视线中。
CI简单流程图
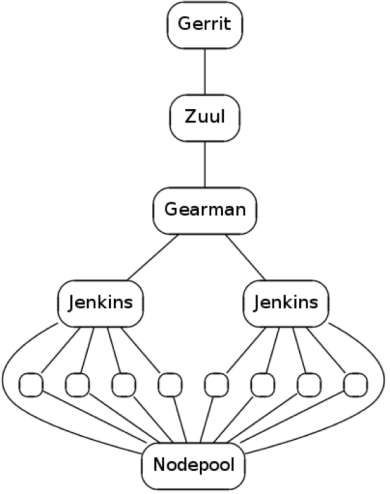
Zuul组件
为了更好的理解什么是Zuul和Zuul到底是怎么工作的,需要介绍一下Zuul有哪些组件
Zuul整体架构
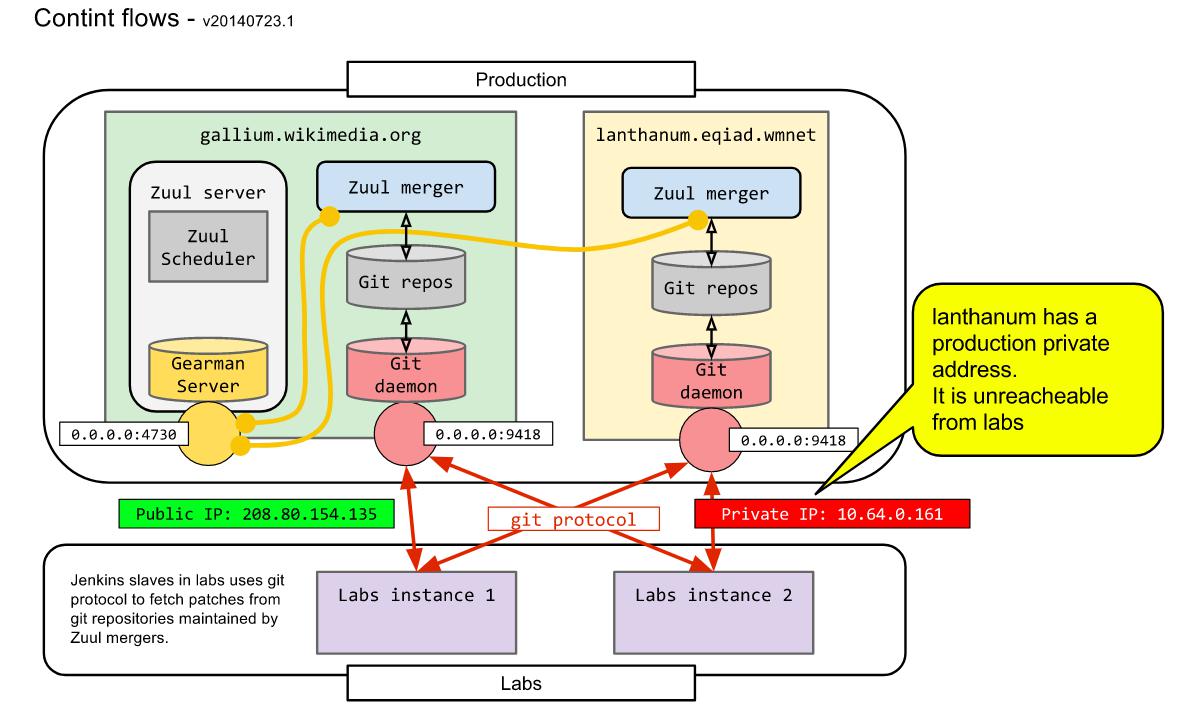
Zuul-server
Zuul-server是Zuul的主要的服务,zuul-server是作为zuul的scheduler,zuul-server从gerrit接收消息,一旦消息被接收到,zuul-server就建立工作流程,并把处理结果返回给gerrit Zuul-server跟gerrit组件交流是通过执行“gerrit stream-events”,然后等待gerrit返回的信息,另外,zuul-server也与Gearman进行通讯
Gearman
Jenkins的设计初衷并不用于并行执行,它设计中某些点使用到了全局锁,因此在Jenkins的slave节点增加到一定数量后(大约100台),Jenkins的master节点就会出现问题而成为瓶颈。同时master节点是单点部署,无法完成HA等处理。为了扩展Jenkins而引入了Gearman。
简单来说,Gearman是一个用来扩展Jenkins的一种协议,而且Gearman一开始并不是专门为Zuul开发的,但是Gearman很好的符合了Zuul的需求,因此OpenStack采用Gearman来扩展Zuul对Jenkins的调度。
在配置的时候可以选择单独创建Gearman-server或者是使用Zuul来部署Gearman,具体在/etc/zuul/zuul.conf里面进行配置:
1
2
3
4
5
[gearman_server]
listen_address = 127.0.0.1
log_config = /etc/zuul/gearman-logging.conf
start = true
把start改成true,zuul服务就会启动并管理Gearman进程
Zuul-merger
这里不要被这个组件的名字所误导了,这个组件并不是当代码全部通过测试后用来merge到主干的
当开发者提交一个change后,zuul-merger把这个change merge到一个本地forked repository中 ,这样就可以进行下一步的测试了。
可以把zuul-merger单独部署在一台服务器上也可以进行高可用部署,即部署在多台服务器上组成zuul-merger的集群
在zuul的配置文件 /etc/zuul/zuul.conf下可以对zuul-merger进行配置,在 [merger] section下面
1
2
3
4
5
6
[merger]
git_dir = /var/lib/zuul/git
log_config = /etc/zuul/merger-logging.conf
pidfile = /var/run/zuul-merger/zuul-merger.pid
zuul_url = 127.0.0.1
- git_dir是zuul对Git repository的一个copy
- Log_config是配置zuul-merger的log目录
- zuul_url是zuul server的url,这个url可能有多个(zuul集群的情况下)
Zuul-cloner
Zuul-cloner不像其他组件,它没有Damon,只有一个client,用来创建job的workspace
Zuul Workflow
下图是解释当一个patch提交给gerrit的时候zuul的workflow是怎么样的
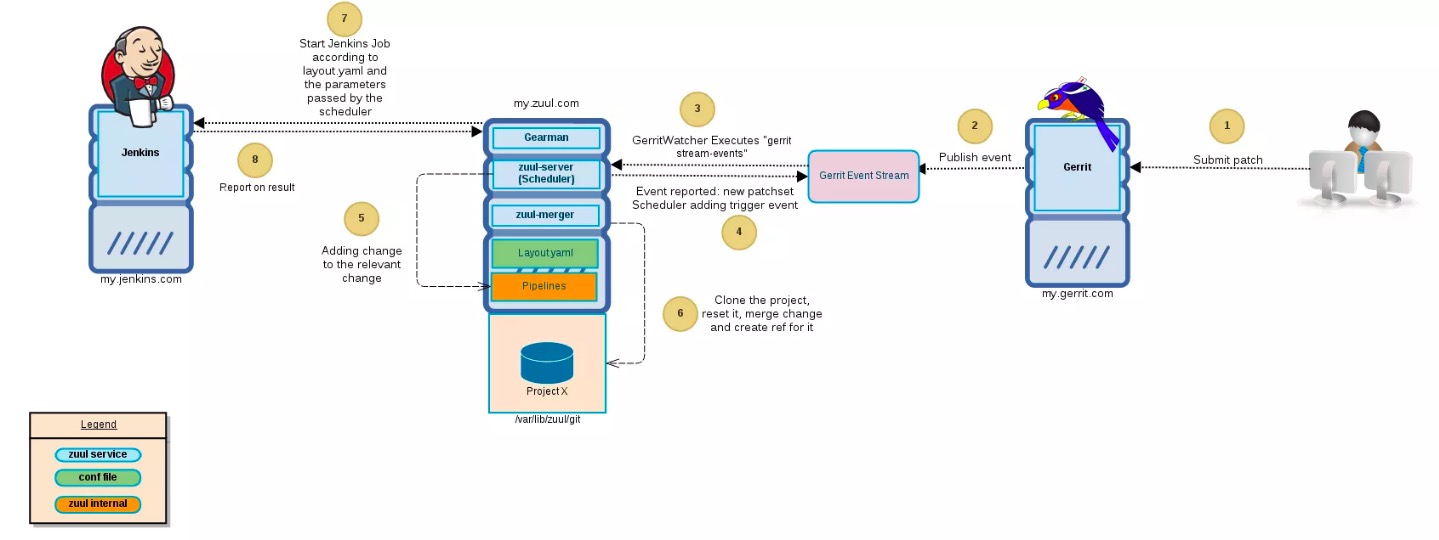
Gerrit
用户的patch是提交给Gerrit的,也可以是一个新的commit
一旦这个patch被提交上来,Gerrit就会publish一个event,通知其他服务来处理这个event,如Zuul、Jenkins等
Zuul Server
Zuul-server根据zuul.conf的配置来启动相应的关联进程,Zuul server会先起一个进程叫GerritWatcher,用来listen从Gerrit那边传过来的event(步骤3),在注册好所有的连接后,zuul-server会起一个Gearman,zuul-server同时会启动Gearman和Scheduler
当一个Gerrit的event被publish后,GerritWatcher就会通知scheduler,scheduler先会去检查这个event是否合法(根据layout.yaml里面定义的规则),如果通过,便会触发一个trigger event(步骤4)
Scheduler接着处理这个event,并把这个event添加到一个相关的pipeline里面(步骤5,也是根据layout.yaml里面定义的规则),接下去就是pipeline来处理这个event了,scheduler也会去检查这个event是否依赖于其他的event
Zuul Merger
当scheduler触发完成trigger event后,把整个代码克隆下来,并把更改的代码并入主干的工作是由zuul-merger来完成的。在步骤6中,merger会从gearman那边获得一个“merge job”的信息,里面包括项目的名称,分支信息,change number和ref等信息。第一步merger需要确认这个commit是不是重复的,如果是,那么就返回已经发生的commit,如果不是,那么继续下一步工作。
HEAD ref重置完成后,如果ref指向了一个不可用的分支,那么zuul就会自动选择第一个可用的分支,然后merger会通过“git fetch”来update repo,再checkout。
接下来merger尝试merge更改到repo上,如果merge成功,那么就会在zuul-server中创建一个新的reference到repo中,最后,merger会返回一个动作完成的信息。
Gearman & Jenknis
现在repo已经准备完成,在上面merger的工作完成之后,现在需要测试这个代码的更改。这步操作其实是scheduler来做的,但是需要配合Gearman来执行。Scheduler发送
Gearman接着把数据发送给Jenkins,Jenkins可能是一个集群,Jenkins在测试完成后会把结果返回给zuul,zuul再去通知gerrit是否去merge这个更改。
是否必须使用Jenkins
OpenStack社区考虑过不再使用Jenkins,只使用Zuul来代替,但是如果你的CI系统跟Jenkins强绑定的话,系统中使用了很多Jenkins的plugin,那么再去转换到non-Jenkins的环境中会有比较大的困难。当然可以慢慢利用Zuul来替换Jenkins,但是如果一定要使用Jenkins的话,那么就需要“Jenkins Gearman”这个plugin来提供支持。
Pipelines
Pipelines是Zuul重要的组成部分,每一个gerrit的change都会由一个或者多个Pipelines来进行处理
Upsteam
非Openstack核心团队的人员可以在评审代码后作出+1(好)、0(无评价)、-1(不建议合并)的评价。核心团队的成员可以给出非核心成员可给出的所有评价,此外还可以给出+2(好,approved)、-2评价(不要提交)。
标签属性中另外一列为“Verified”。只有Gerrit的非交互用户(non-interactive users)如Jenkins,才能在此属性上添加Verified标签。Verified一列可设置的值为+1(check pipeline测试通过)、-1(check pipeline测试未通过)、+2(gate pipeline测试通过)、-2(gate pipeline测试未通过)。此外,第三方搭建的外部测试平台也属于非交互用户,但是只能设置+1、-1。
Pipeline也有很多种
- periodic – 周期性工作的pipeline,比如用于非工作时间做常规的测试
- expermental – 如果你有一个新项目,但是不知道它是怎么工作的,那么可以用于这个expermental pipeline
- pre-release – 触发的job是归于一个新的pre-release tags
- release – 触发的job是归于一个release tags
定制化Pipelines
可以通过配置Zuul来定制化pipelines,可以通过更改zuul layout配置文件
下面是一个配置例子
1
2
3
4
5
6
7
8
9
10
11
12
13
- name: test
manager: IndependentPipelineManager
source: gerrit_internal
trigger:
my_gerrit:
- event: patchset-created
success:
my_gerrit:
verified: 1
failure:
my_gerrit
verified: -1
可以自定义一个pipeline,取名为test,如果pipeline运行成功,那么返回给gerrit +1,如果失败,那么返回给gerrit -1
上面的配置文件中还有
1
2
manager: IndependentPipelineManager
这个是用来决定pipeline具体是怎么工作的
IndependentPipelineManager
IndependentPipelineManager是当pipeline在处理信息是不需要关心信息处理的顺序的时候使用,在一些patch提交时,在其他test正在运行的时候,也不会对这个patch提交产生影响,当前提交的patch是相对独立的,那么就可以使用IndependentPipelineManager
DependentPipelineManager
DependentPipelineManager则是当pipeline在处理信息是不需要关心信息处理的顺序的时候使用,如果当你同时提交了多个patch,当一个patch test failed的时候,那么同时提交的相关联的patch都需要再次test一次。
Zuul同时还可以很好的处理具有复杂依赖关系的多个patch。它能监控正在执行的任务,并可提前结束掉因依赖的patch测试失败而必定失败的测试任务。
参考文献
http://stackeye.com/2014/06/openstack-ci/
https://docs.openstack.org/infra/manual/zuulv3.html